Don’t Blind Your VLA: Aligning Visual Representations for OOD Generalization
Abstract
The growing success of Vision-Language-Action (VLA) models stems from the promise that pretrained Vision-Language Models (VLMs) can endow agents with transferable world knowledge and vision-language (VL) grounding, laying a foundation for action models with broader generalization. Yet when these VLMs are adapted to the action modality, it remains unclear to what extent their original VL representations and knowledge are preserved. In this work, we conduct a systematic study of representation retention during VLA fine-tuning, showing that naive action fine-tuning leads to degradation of visual representations. To characterize and measure these effects, we probe VLA's hidden representations and analyze attention maps, further, we design a set of targeted tasks and methods that contrast VLA models with their counterpart VLMs, isolating changes in VL capabilities induced by action fine-tuning. We further evaluate a range of strategies for aligning visual representations and introduce a simple yet effective method that mitigates degradation and yields improved generalization to out-of-distribution (OOD) scenarios. Taken together, our analysis clarifies the trade-off between action fine-tuning and the degradation of VL representations and highlights practical approaches to recover inherited VL capabilities.
Introduction
Vision–Language Models (VLMs) have achieved remarkable success by leveraging large-scale multimodal datasets to learn semantically grounded and generalizable visual–language representations. These advances have inspired extending VLMs to embodied domains. Vision–Language–Action (VLA) models adapt pretrained VLMs to robotic action prediction, aiming to transfer their semantic priors into action spaces for generalization to unseen scenes and tasks. However, fine-tuning often causes overfitting and degradation of visual–language representations. Prior works attempted to mitigate this via auxiliary reasoning objectives, co-training, or freezing VL backbones, but no effective solution exists for representation drift during supervised fine-tuning. We systematically investigate this degradation and propose a lightweight Visual Representation Alignment method, motivated by the Platonic Representation Hypothesis, which posits that large models converge toward shared semantic spaces. Our approach constrains VLA visual features to remain aligned with a generalist vision encoder during fine-tuning, preserving semantic grounding while adapting to robotic actions. Applied to the Simpler benchmark, this method yields up to a 10% relative gain in out-of-distribution generalization with negligible computational overhead.
Method
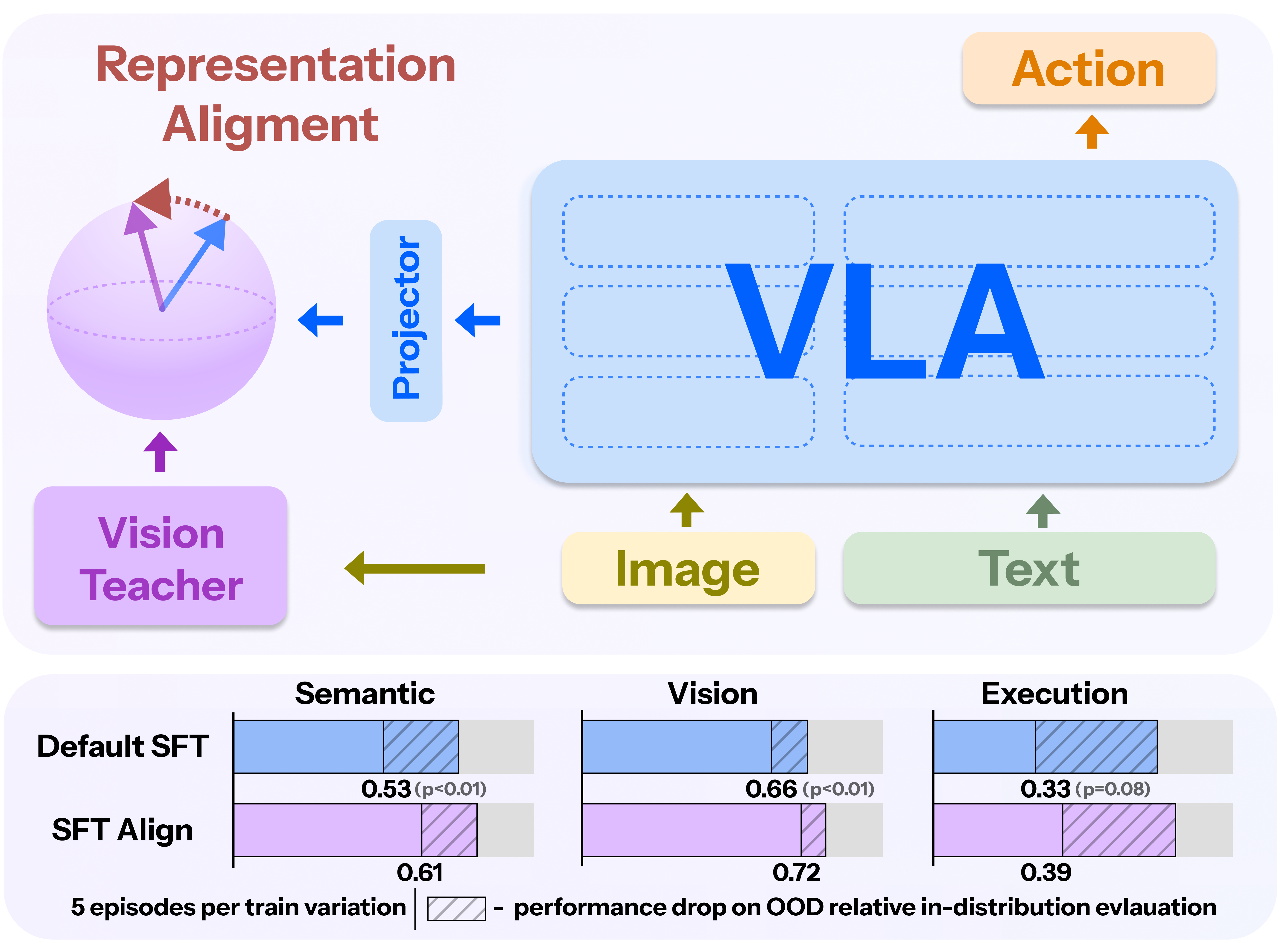
Overview of the proposed method. (a, b) Training pipeline with visual alignment loss - no extra overhead, only precomputed teacher features and a lightweight regularization term during SFT. (c) Conceptual illustration of the loss landscape for VL tasks: the core idea is to optimize the model with respect to the action objective while preserving performance on VL understanding.
Following the Platonic Representation Hypothesis, we assume that high-performing vision, language, and multimodal models tend to converge toward a shared latent representation space that captures general semantic and perceptual structure across different modalities. Each modality offers a compatible view of this space, and a VLA model can be regarded as a policy that grounds its decision-making in a subset of these multimodal representations. Task-specific fine-tuning can induce representational drift, pulling internal VLA features away from this generalized space causing it to lose connection to broad, transferable semantic. We address this with Visual Representation Alignment: a lightweight objective that anchors the VLA’s visual representations to a frozen, semantically rich vision teacher.
Visual representation alignment
Let the frozen teacher encoder be \(E^{*}_{\mathrm{img}}\) and the VLA’s visual features live in \(\mathbb{R}^{d_e}\). We introduce a projector \(P_{\phi}:\mathbb{R}^{d_e}\!\to\!\mathbb{R}^{d_t}\) to map VLA features into the teacher space. For an input image \(I\) producing \(k\) patch embeddings, the teacher targets are \(\mathbf{z}_{1:k}=E^{*}_{\mathrm{img}}(I)\) and the projected VLA features are \(\mathbf{u}_{1:k}=P_{\phi}(\mathbf{h}_{1:k})\). We maximize patch-wise similarity between projected VLA features and teacher embeddings to encourage perceptual consistency and prevent degradation:
\[ \mathcal{L}_{\text{align}} = -\frac{1}{k}\sum_{j=1}^{k}\operatorname{sim}\!\big(\mathbf{u}_j,\mathbf{z}_j\big), \]
The training objective augments the standard VLA policy loss with the alignment term:
\[ \mathcal{L}_{\text{total}} = \mathcal{L}_{\text{VLA}} + \lambda\,\mathcal{L}_{\text{align}}, \qquad \lambda>0. \]
Gradients update the VLA encoders and Transformer backbone, while the teacher \(E^{*}_{\mathrm{img}}\) remains frozen, serving as a fixed perceptual prior that preserves broad visual–semantic structure throughout fine-tuning.
VL-Think Task Suite

VL-Think benchmark. A comprehensive suite of tasks designed to diagnose vision–language–action generalization across semantic, visual, and execution variations. Each subset probes a specific dimension of out-of-distribution reasoning in embodied settings.
Existing VLA benchmarks mainly evaluate task execution under distribution shifts - changes in objects, scenes, or textures, but provide limited insight into whether pretrained vision-language (VL) knowledge is preserved after action fine-tuning. To address this gap, we introduce the VL-Think Task Suite, a diagnostic suite assessing the transfer of VL understanding and knowledge from VLMs to VLAs independently of low-level control. The suite focuses on whether models retain the ability to interpret visual symbols, compositional cues, and categorical relations rather than pure manipulation skills. Control complexity is intentionally minimized so that any degradation reflects a loss of VL understanding.
Evaluation Protocol
We evaluate both VLA and VLM models.
- VLA evaluation: The agent observes RGB frames and natural-language instructions. Success is recorded when a known object is placed on the correct target board, directly measuring grounding of language in visual categories.
- VLM evaluation: The same scenes are shown statically with the probe “Do you see the <board_name>?”. Success requires correctly identifying both the target board and its location, providing an action-free measure of semantic grounding.
VL-Think Description
VL-Think builds on the Simpler benchmark using a
WidowX-250S arm in a simplified pick-and-place setup.
Each episode spawns one familiar object (a carrot) and several planar boards
textured with abstract categories (icons, shapes, numerals).
A language instruction specifies a target concept and the agent succeeds if it places the object on the matching board.
The suite includes eight board-selection tasks probing distinct knowledge types:
Shape, Color, Traffic,
Laundry, Weather, Arrow,
Public information, and Numeral parity.
By fixing the object and motor control, VL-Think isolates semantic
understanding while bounding execution complexity.
VL Representations Analysis
We investigate how VL representations evolve in VLA models after action fine-tuning. Specifically, we ask whether semantic grounding and knowledge transfer from pretrained VLMs are preserved. To assess degradation, we combine three complementary analyses: attention map analysis - examines how accurately the model attends to objects referenced in text, t-SNE visualization - illustrates the latent space structure formed by instruction-related token embeddings, VL-Think evaluation - measures transfer of pretrained VL knowledge and understanding to VLA policies. Together, these diagnostics reveal whether fine-tuning erodes visual grounding, latent organization, or domain knowledge.
Attention Sink
Question: "Do you see plate?"

Question: "Do you see baguette?"

Question: "Do you see hamburger?"
Attention maps from middle transformer layers (where VL fusion peaks) show distinct behaviors across models. Qwen2.5-VL maintains sharp, object-aligned focus, whereas OpenVLA displays substantial degradation in attention quality: the maps become diffuse, noisy, and weakly correlated with the target object indicating attention sink. Our Visual Representation Alignment method restores object-centric focus and clear attention boundaries.
Representation Collapse
t-SNE visualization of token embeddings. PrismaticVLM and Qwen2.5-VL maintain well-separated clusters for target objects, while OpenVLA shows strong overlap across classes, indicating that action fine-tuning leads to representation collapse.
Using t-SNE on COCO dataset samples, we compare embeddings of Qwen2.5-VL, PrismaticVLM, and OpenVLA. The former two retain well-separated clusters and semantically organized latent space, while OpenVLA shows overlapping, collapsed clusters evidence that fine-tuning for robot control disrupts the structured organization of its inherited representations and induces representation collapse.
Domain Forgetting
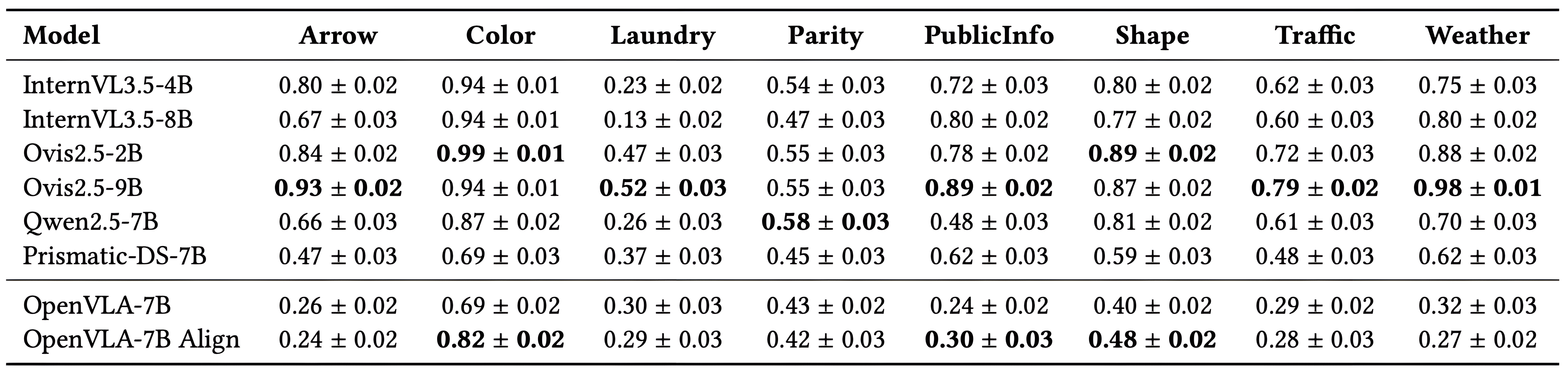
VL-Think VLM results across eight domains. The benchmark reveals a strong correlation between VL understanding and model scale: larger VLMs achieve higher overall success. However, OpenVLA–7B fine-tuned for action shows clear VL degradation: its performance drops markedly compared to the original PrismaticVLM across all domains except color, where VL skills remain largely preserved.
Evaluation on the VL-Think suite compares
OpenVLA–7B with its pretrained base
PrismaticVLM and several state-of-the-art VLMs.
Strong VLMs show high success across domains, reflecting robust semantic grounding.
Yet action fine-tuning induces domain-specific forgetting: OpenVLA–7B suffers major drops,
especially in symbolic and abstract categories (traffic, arrows, public information, weather).
We hypothesize that VLA models lose knowledge about domains that are absent in robotics fine-tuning datasets. Only Color transfer persists,
as color cues remain useful for control and are implicitly represented in robotics data.
Experiments
Evaluation Setup
We evaluate our approach in Simpler-based environments using the VL-Think Task Suite and the benchmark introduced in RL4VLA measuring VLA generalization across Vision (textures, noise), Semantics (unseen objects, paraphrases, distractors), and Execution (randomized poses, object changes). OOD evaluation holds out one variation per axis, including 9 new objects, 16 unseen receptacles, and 16 distractor backgrounds. We collect 1,400 expert training episodes using motion planner, covering 16 tables and 16 objects (~5 demonstrations per variation) and evaluate following baselines: Default (standard supervised fine-tuning), Freeze (fine-tuning with a frozen visual encoder), and Align (ours) (fine-tuning with our proposed Visual Representation Alignment method).
Results: OOD Evaluation

OOD generalization performance. Mean ± SD across evaluation environments. The proposed alignment objective yields consistent gains over SFT and frozen-encoder baselines, indicating enhanced robustness to out-of-distribution domain shifts.
Our alignment method yields consistent improvements across all evaluation axes. This result underscores the effectiveness of Visual Representation Alignment in enhancing robustness to visual shifts, text instruction variations, texture changes, and background perturbations that frequently occur in real-world scenarios In contrast, the Freeze baseline fails completely, confirming that static visual features desynchronize from evolving action layers. Visual alignment acts as a regularizer that preserves general semantics during adaptation to new environments.
Results: Linear Probing

Linear probing results. OpenVLA-Align retains stronger features than both the pretrained and SFT variants, closing much of the gap to the C-RADIOv3 teacher and demonstrating improved semantic consistency after action fine-tuning.
Linear probing on ImageNet-100 demonstrates that our proposed Visual Representation Alignment method enhances representations quality, outperforming both the pretrained checkpoint and naive SFT. The alignment objective strengthens semantic consistency and leads to more transferable visual features.
Results: VL-Think
Evaluation on the VL-Think Suite
shows that our proposed Visual Representation alignment method mitigates domain forgetting
and improves performance in Color and Shape tasks,
occasionally surpassing the PrismaticVLM upper bound. However, limited data diversity
and LoRA capacity constrain recovery
of rarer VL concepts — an important direction for future work.
BibTeX
@misc{kachaev2025dontblindvlaaligning,
title={Don't Blind Your VLA: Aligning Visual Representations for OOD Generalization},
author={Nikita Kachaev and Mikhail Kolosov and Daniil Zelezetsky and Alexey K. Kovalev and Aleksandr I. Panov},
year={2025},
eprint={2510.25616},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2510.25616},
}